Find automation helpers and reference material that streamline Linux administration tasks.
This is the multi-page printable view of this section. Click here to print.
Kernel
Linux Kernel Information
- 1: Soft and Hard Lockups
- 2: Why Kernel Crash Dumps Are Critical for Root Cause Analysis
- 3: Enabling Automatic Kernel Crash Collection with kdump
- 4: Kernel Mode vs User Mode: Privilege Levels and System Call Execution
- 5: Understanding CPU Statistics in Linux (/proc/stat)
1 - Soft and Hard Lockups
Detect, troubleshoot, and simulate Linux kernel soft and hard lockups with the watchdog.
Introduction
Kernel Watchdog
According to Linux Kernel Documentation, the Linux kernel can act as a watchdog to detect both soft and hard lockups.
The Linux Kernel Watchdog is a mechanism that monitors the system for both soft and hard lockups. It is designed to detect when a CPU is stuck in a loop and unable to make progress. When a soft lockup is detected, the watchdog will print a warning message to the system log.
Soft vs. Hard Lockups
Soft Lockup
A ‘softlockup’ is defined as a bug that causes the kernel to loop in kernel mode for more than 20 seconds, without giving other tasks a chance to run. The current stack trace is displayed upon detection and, by default, the system will stay locked up.
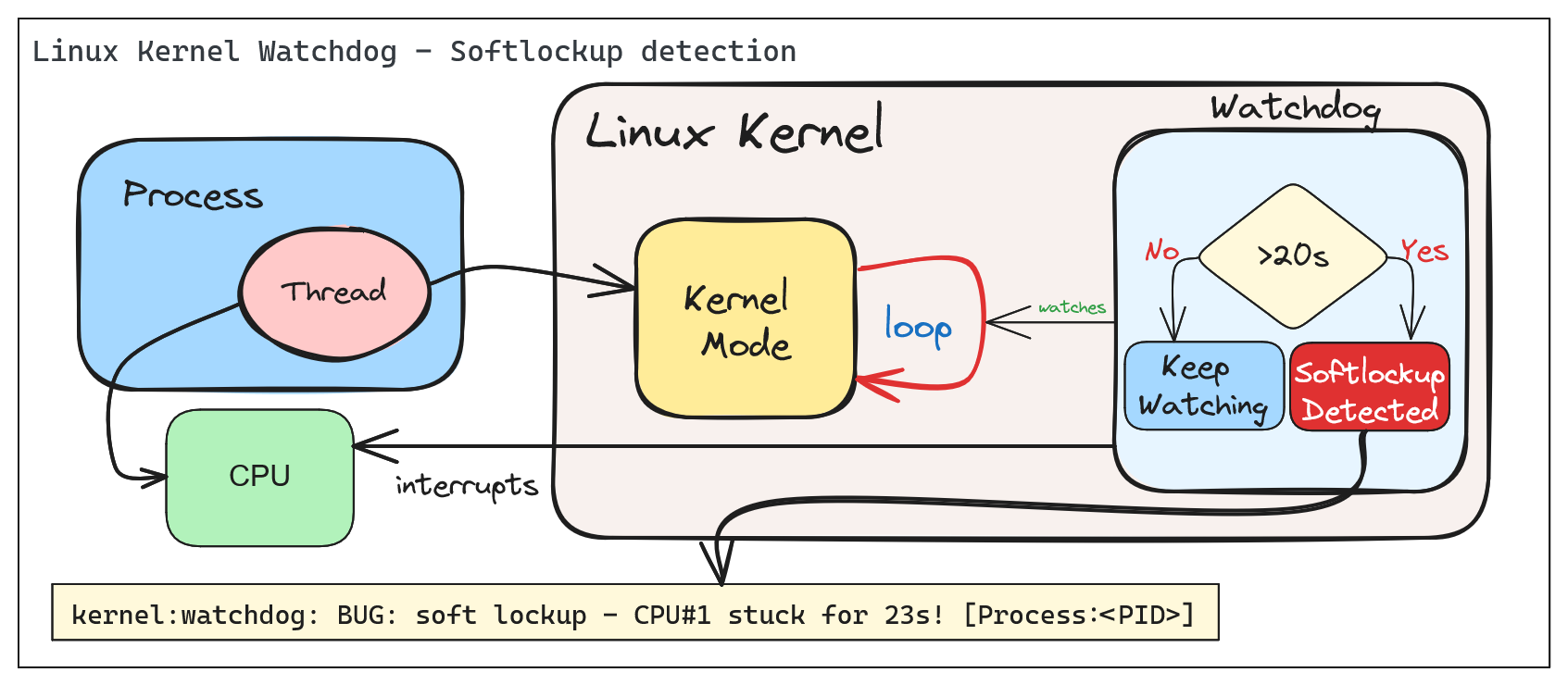
By default the system will display the stack trace and stay locked up. Watchdog can be configured to reboot the system automatically when a soft lockup is detected. This can be done by setting the softlockup_panic parameter to a value greater than zero.
Common error messages:
BUG: soft lockup - CPU#0 stuck for 22s! [swapper/0:1]
Modules linked in: ...
Hard Lockup
A ‘hardlockup’ is defined as a bug that causes the CPU to loop in kernel mode for more than 10 seconds, without letting other interrupts have a chance to run.
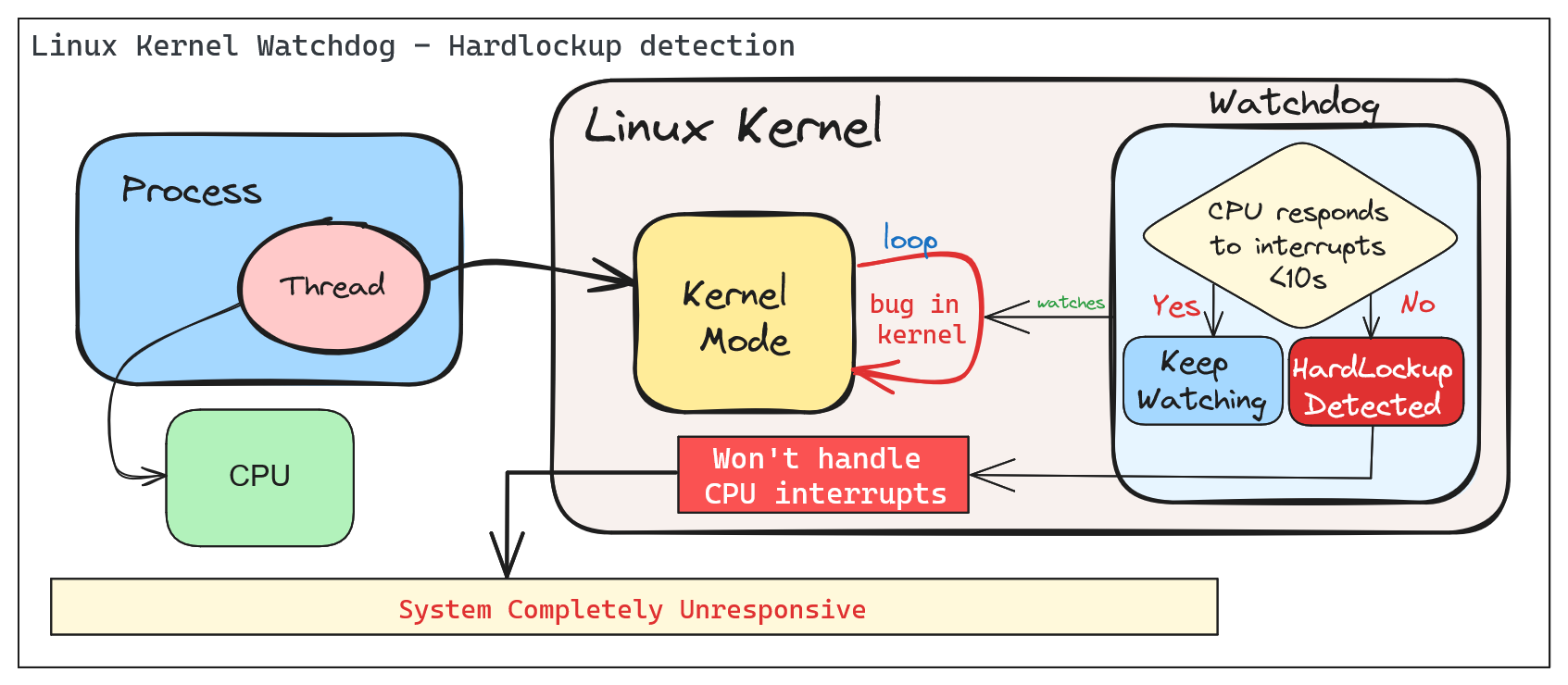
Similar to softlockup, the system will display the stack trace and stay locked up. The watchdog can be configured to reboot the system automatically when a hard lockup is detected. This can be done by setting the hardlockup_panic parameter to a value greater than zero.
Common error messages:
BUG: hard lockup - CPU#0 stuck for 22s! [swapper/0:1]
Modules linked in: ...
Deep Dive into Soft/Hard Lockups
Reacting to soft/hard lockups
Ok, so you have a soft or hard lockup, what now? Here are some steps you can take to troubleshoot and resolve the issue:
The Basics
1. Check the system logs: Look for any error messages or warnings that may indicate the cause of the lockup.
2. Check the CPU load: High CPU load can cause lockups. Use tools like top or htop to monitor CPU usage.
3. Read the watchdog warning message: The watchdog will print a warning message to the system log when a lockup is detected. This message may provide clues as to the cause of the lockup. Usually, the message will include a stack trace that shows where the CPU is stuck, also the name of the process that caused the lockup and it’s PID.
Thresholds
The watchdog has default thresholds for detecting soft and hard lockups. These thresholds can be adjusted to suit your system’s needs. Before changing thresholds, it is important to understand the implications of changing these values. Setting the thresholds too low may result in false positives, while setting them too high may result in missed lockups.
A periodic hrtimer runs to generate interrupts and kick the watchdog job. An NMI perf event is generated every “watchdog_thresh” (compile-time initialized to 10 and configurable through sysctl of the same name) seconds to check for hardlockups. If any CPU in the system does not receive any hrtimer interrupt during that time the ‘hardlockup detector’ (the handler for the NMI perf event) will generate a kernel warning or call panic, depending on the configuration. The watchdog job runs in a stop scheduling thread that updates a timestamp every time it is scheduled. If that timestamp is not updated for 2*watchdog_thresh seconds (the softlockup threshold) the ‘softlockup detector’ (coded inside the hrtimer callback function) will dump useful debug information to the system log, after which it will call panic if it was instructed to do so or resume execution of other kernel code.
Check current threshold:
cat /proc/sys/kernel/watchdog_thresh
10
Update threshold to 30 seconds:
# For temporary change
echo 30 > /proc/sys/kernel/watchdog_thresh
# For permanent change
echo "kernel.watchdog_thresh = 30" >> /etc/sysctl.conf
sysctl -p
Advanced Troubleshooting
The watchdog can be configured to panic the system when a lockup is detected. This can be done by setting the softlockup_panic or hardlockup_panic parameters to a value greater than zero.:
# Enable panic on soft lockup
echo 1 > /proc/sys/kernel/softlockup_panic
# Enable panic on hard lockup
echo 1 > /proc/sys/kernel/hardlockup_panic
In combination with crash dump, you can get a full dump of the system state when a lockup is detected. This can be useful for debugging the issue.
Step-by-step guide for this recipe: 1. Enable crash dump in the kernel configuration. Make sure that it’s collecting memory dumps when a kernel panic occurs. 2. Configure the kernel to reboot the system when a lockup is detected. 3. Proceed by analyzing the crash dump to identify the cause of the lockup.
Demo - Creating a Softlockup and understanding the watchdog output
Simulating a Soft Lockup
For the example below, we will simulate a soft lockup by loading a kernel module design to test if watchdog and lockup detection are working as expected.
Test module to generate lockups: CONFIG_TEST_LOCKUP
Note: When installing Linux Kernel modules, make sure: You are using the correct version of the kernel module for your kernel version. (Browse kernel config source code and match your kernel version: Example for v6.9.5). And, that you have the necessary kernel headers installed.
The following parameters are available to simulate a variety of lockups:
# modinfo soft.ko
filename: /root/CONFIG_TEST_LOCKUP/soft.ko
description: Test module to generate lockups
author: Konstantin Khlebnikov <[email protected]>
license: GPL
srcversion: 302B4AE69F898F7B25CABF8
depends:
retpoline: Y
name: soft
vermagic: 5.15.0-1064-azure SMP mod_unload modversions
parm: time_secs:lockup time in seconds, default 0 (uint)
parm: time_nsecs:nanoseconds part of lockup time, default 0 (uint)
parm: cooldown_secs:cooldown time between iterations in seconds, default 0 (uint)
parm: cooldown_nsecs:nanoseconds part of cooldown, default 0 (uint)
parm: iterations:lockup iterations, default 1 (uint)
parm: all_cpus:trigger lockup at all cpus at once (bool)
parm: state:wait in 'R' running (default), 'D' uninterruptible, 'K' killable, 'S' interruptible state (charp)
parm: use_hrtimer:use high-resolution timer for sleeping (bool)
parm: iowait:account sleep time as iowait (bool)
parm: lock_read:lock read-write locks for read (bool)
parm: lock_single:acquire locks only at one cpu (bool)
parm: reacquire_locks:release and reacquire locks/irq/preempt between iterations (bool)
parm: touch_softlockup:touch soft-lockup watchdog between iterations (bool)
parm: touch_hardlockup:touch hard-lockup watchdog between iterations (bool)
parm: call_cond_resched:call cond_resched() between iterations (bool)
parm: measure_lock_wait:measure lock wait time (bool)
parm: lock_wait_threshold:print lock wait time longer than this in nanoseconds, default off (ulong)
parm: disable_irq:disable interrupts: generate hard-lockups (bool)
parm: disable_softirq:disable bottom-half irq handlers (bool)
parm: disable_preempt:disable preemption: generate soft-lockups (bool)
parm: lock_rcu:grab rcu_read_lock: generate rcu stalls (bool)
parm: lock_mmap_sem:lock mm->mmap_lock: block procfs interfaces (bool)
parm: lock_rwsem_ptr:lock rw_semaphore at address (ulong)
parm: lock_mutex_ptr:lock mutex at address (ulong)
parm: lock_spinlock_ptr:lock spinlock at address (ulong)
parm: lock_rwlock_ptr:lock rwlock at address (ulong)
parm: alloc_pages_nr:allocate and free pages under locks (uint)
parm: alloc_pages_order:page order to allocate (uint)
parm: alloc_pages_gfp:allocate pages with this gfp_mask, default GFP_KERNEL (uint)
parm: alloc_pages_atomic:allocate pages with GFP_ATOMIC (bool)
parm: reallocate_pages:free and allocate pages between iterations (bool)
parm: file_path:file path to test (string)
parm: lock_inode:lock file -> inode -> i_rwsem (bool)
parm: lock_mapping:lock file -> mapping -> i_mmap_rwsem (bool)
parm: lock_sb_umount:lock file -> sb -> s_umount (bool)
We will simulate a soft lockup by loading the module with the following parameters:
insmod soft.ko time_secs=35 iterations=1 all_cpus=0 state="R"
Where:
time_secs=35- Lockup time in secondsiterations=1- Lockup iterationsall_cpus=0- Trigger lockup at all CPUs at oncestate="R"- Wait in ‘R’ running state
After loading the module, the system will be locked up for 35 seconds. The watchdog will detect the soft lockup and print a warning message to the system log.
Understanding the watchdog output
The watchdog warning message
[ 568.503455] watchdog: BUG: soft lockup - CPU#1 stuck for 26s! [insmod:5912]
[ 568.508018] Modules linked in: soft(OE+) nls_iso8859_1 kvm_intel kvm crct10dif_pclmul crc32_pclmul ghash_clmulni_intel binfmt_misc sha256_ssse3 sha1_ssse3 aesni_intel crypto_simd cryptd joydev hid_generic serio_raw hyperv_drm drm_kms_helper syscopyarea hid_hyperv sysfillrect sysimgblt hid fb_sys_fops hv_netvsc hyperv_keyboard cec rc_core sch_fq_codel drm i2c_core efi_pstore ip_tables x_tables autofs4
The watchdog warning message includes the following information:
BUG: soft lockup- Indicates that a soft lockup was detectedCPU#1 stuck for 26s!- Indicates that CPU#1 was stuck for 26 seconds[insmod:5912]- Indicates that the process with PID 5912 caused the lockup (in this case, theinsmodprocess)Modules linked in (...)- Lists the kernel modules that were loaded at the time of the lockup
The stack trace
[ 568.508074] Call Trace:
[ 568.508075] <IRQ>
[ 568.508079] ? show_regs.cold+0x1a/0x1f
[ 568.508085] ? watchdog_timer_fn+0x1c4/0x220
[ 568.508089] ? softlockup_fn+0x30/0x30
[ 568.508092] ? __hrtimer_run_queues+0xca/0x1d0
[ 568.508095] ? hrtimer_interrupt+0x109/0x230
[ 568.508097] ? hv_stimer0_isr+0x20/0x30
[ 568.508101] ? __sysvec_hyperv_stimer0+0x32/0x70
[ 568.508104] ? sysvec_hyperv_stimer0+0x7b/0x90
[ 568.508109] </IRQ>
[ 568.508110] <TASK>
[ 568.508111] ? asm_sysvec_hyperv_stimer0+0x1b/0x20
[ 568.508116] ? delay_tsc+0x2b/0x70
[ 568.508118] __const_udelay+0x43/0x50
[ 568.508122] test_wait+0xc6/0xe0 [soft]
[ 568.508129] test_lockup+0xd9/0x270 [soft]
[ 568.508133] test_lockup_init+0x891/0x1000 [soft]
[ 568.508137] ? 0xffffffffc084f000
[ 568.508139] do_one_initcall+0x48/0x1e0
[ 568.508143] ? __cond_resched+0x19/0x40
[ 568.508146] ? kmem_cache_alloc_trace+0x15a/0x420
[ 568.508150] do_init_module+0x52/0x230
[ 568.508154] load_module+0x1294/0x1500
[ 568.508159] __do_sys_finit_module+0xbf/0x120
[ 568.508162] ? __do_sys_finit_module+0xbf/0x120
[ 568.508165] __x64_sys_finit_module+0x1a/0x20
[ 568.508168] x64_sys_call+0x1ac3/0x1fa0
[ 568.508170] do_syscall_64+0x54/0xb0
[ 568.508174] ? __audit_syscall_exit+0x265/0x2d0
[ 568.508177] ? ksys_mmap_pgoff+0x14b/0x2a0
[ 568.508182] ? exit_to_user_mode_prepare+0x54/0x270
[ 568.508185] ? syscall_exit_to_user_mode+0x27/0x40
[ 568.508187] ? do_syscall_64+0x61/0xb0
[ 568.508189] entry_SYSCALL_64_after_hwframe+0x67/0xd1
[ 568.508191] RIP: 0033:0x7f860d3fa95d
[ 568.508194] Code: 00 c3 66 2e 0f 1f 84 00 00 00 00 00 90 f3 0f 1e fa 48 89 f8 48 89 f7 48 89 d6 48 89 ca 4d 89 c2 4d 89 c8 4c 8b 4c 24 08 0f 05 <48> 3d 01 f0 ff ff 73 01 c3 48 8b 0d 03 35 0d 00 f7 d8 64 89 01 48
[ 568.508196] RSP: 002b:00007ffd21043e88 EFLAGS: 00000246 ORIG_RAX: 0000000000000139
[ 568.508198] RAX: ffffffffffffffda RBX: 0000562af1c447d0 RCX: 00007f860d3fa95d
[ 568.508199] RDX: 0000000000000000 RSI: 0000562af1c442a0 RDI: 0000000000000003
[ 568.508200] RBP: 0000000000000000 R08: 0000000000000000 R09: 00007ffd21044048
[ 568.508201] R10: 0000000000000003 R11: 0000000000000246 R12: 0000562af1c442a0
[ 568.508202] R13: 0000000000000000 R14: 0000562af1c447a0 R15: 0000562af1c442a0
[ 568.508204] </TASK>
[ 577.859869] soft: Finish on CPU1 in 34727950300 ns
[ 577.859874] soft: FINISH in 34727963600 ns
The stack trace shows where the CPU was stuck and provides information about the process that caused the lockup.
Important information from the stack trace:
IRQ- Indicates that the CPU was in an interrupt context when the lockup occurred.

TASK- Indicates what calls where being executed when the lockup occurred.
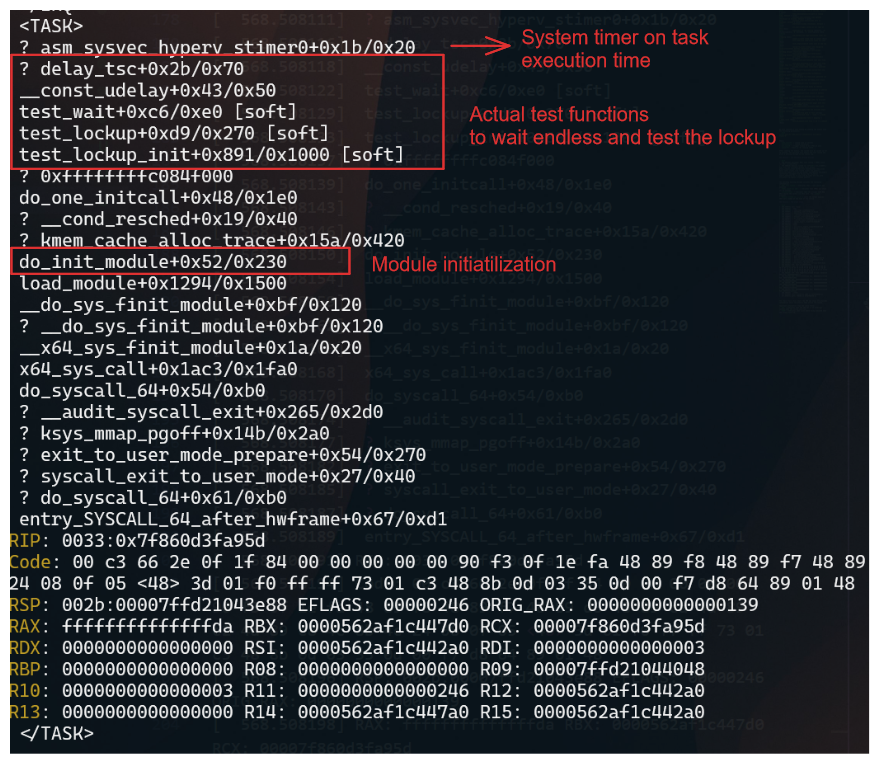
When comparing with source code, you can identify the function that caused the lockup. In this case, the test_wait function in the soft module caused the lockup.
static void test_wait(unsigned int secs, unsigned int nsecs)
{
if (wait_state == TASK_RUNNING) {
if (secs)
mdelay(secs * MSEC_PER_SEC);
if (nsecs)
ndelay(nsecs);
return;
}
__set_current_state(wait_state);
if (use_hrtimer) {
ktime_t time;
time = ns_to_ktime((u64)secs * NSEC_PER_SEC + nsecs);
schedule_hrtimeout(&time, HRTIMER_MODE_REL);
} else {
schedule_timeout(secs * HZ + nsecs_to_jiffies(nsecs));
}
}
Why did it hang?
- The
test_waitfunction was waiting in theTASK_RUNNINGstate, which caused the CPU to be stuck in a loop. - Since we are loading a module, the execution will be in kernel mode, and the watchdog will detect the lockup.
- The mdelay function was used to delay the execution of the function for a specified number of milliseconds. In this case, the function was delayed for 35 seconds, which caused the lockup.
Final Thoughts
The Linux Kernel Watchdog is a powerful tool for detecting soft and hard lockups. By understanding how the watchdog works and how to react to lockups, you can troubleshoot and resolve issues more effectively. Remember to check the system logs, CPU load, and watchdog warning messages when a lockup occurs. By following best practices and using advanced troubleshooting techniques, you can identify the root cause of lockups and take steps to prevent them in the future.
2 - Why Kernel Crash Dumps Are Critical for Root Cause Analysis
Deep-dive on using vmcore crash dumps for postmortem kernel debugging, including real-world kernel bug and OOM workflows.
Postmortem Kernel Forensics with vmcore
Summary
When the Linux kernel panics, there is no userspace stack, no application logs, and often no intact filesystems. The only canonical, lossless record of the kernel’s terminal state is the crash dump (vmcore). Without vmcore, you are constrained to heuristics and guesswork; with vmcore, you can deterministically reconstruct CPU state, task scheduling, memory allocators, locks, timers, and subsystems at the exact point of failure. This is the difference between timeline narratives and hard proof.
What a vmcore Captures (and Why It Matters)
- CPU architectural state: general-purpose registers, control registers, MSRs, per-CPU contexts.
- Full kernel virtual memory snapshot: page tables, slab caches, VFS dentries/inodes, networking stacks, block layer queues, and device driver state.
- Task list and scheduler state:
task_struct, runqueues, RT/DL classes, stop machine contexts. - Lock state:
mutex,spinlock_towners, wait queues, and contention points. - Timers/workqueues/interrupts: pending timers, softirqs, tasklets, IRQ threads, NMI backtraces.
With unstripped vmlinux and kernel debuginfo, these structures become symbol-resolved and type-aware in tools like crash and gdb.
Minimal Prerequisites for a Useful Dump
- Reserve crash kernel memory at boot:
crashkernel=auto(or a fixed size appropriate to RAM and distro guidance). - Ensure
kdumpservice is active and the dump target has write bandwidth and space (prefer raw disk/LVM or fast local FS; only use NFS/SSH if necessary). - Keep exact-matching debuginfo for the running kernel build:
- Uncompressed
vmlinuxwith full DWARF and symbols. - Matching
System.mapand all loaded module debuginfo (e.g.,kernel-debuginfo,kernel-debuginfo-commonon RHEL/Fedora;linux-image-…-dbgsymon Debian/Ubuntu repositories).
- Uncompressed
- Persist critical panic policies:
sysctl -w kernel.panic_on_oops=1
sysctl -w kernel.unknown_nmi_panic=1
sysctl -w kernel.panic_on_unrecovered_nmi=1
sysctl -w vm.panic_on_oom=2 # 1=panic on OOM, 2=panic if no killable task
sysctl -w kernel.panic=10 # auto-reboot N seconds after panic
Persist via /etc/sysctl.d/*.conf as needed. For manual testing, enable SysRq and force a controlled crash:
echo 1 | sudo tee /proc/sys/kernel/sysrq
echo c | sudo tee /proc/sysrq-trigger
Acquisition Pipeline and Size Reduction
makedumpfile can filter non-essential pages to reduce vmcore size and I/O time without destroying forensics value. Recommended options:
makedumpfile -l --message-level 1 \
-d 31 \
/proc/vmcore /var/crash/vmcore.filtered
-d 31drops cache pages, free pages, user pages, and unused memory; tune masks per incident.- Always retain an unfiltered copy during critical investigations if space allows.
Core Tooling
crash: purpose-built kernel postmortem shell usingvmlinuxDWARF types.gdbwithvmlinux: useful for advanced symbol work and scripted analysis.vmcore-dmesg: extracts oops logs and last-kmsg from the dump.
Launch crash with debuginfo and module path:
crash /usr/lib/debug/lib/modules/$(uname -r)/vmlinux /var/crash/vmcore
Typical initial commands in crash:
sys # kernel, uptime, panic info
ps # task list summary
bt # backtrace of current task (set with 'set' or '-p PID')
log # kernel ring buffer extracted from vmcore
kmem -i # memory info: zones, nodes, reclaimers
files -p <PID> # per-process file descriptors
dev -d # device list & drivers
irq # IRQ and softirq state
foreach bt # backtrace all tasks (can be heavy on large systems)
Example 1 — Kernel Bug/Oops Leading to Panic
Symptoms at runtime: abrupt reboot, serial console shows BUG/oops with taint flags; no userspace core dumps.
Postmortem workflow:
vmcore-dmesg /var/crash/vmcore | less
Look for signatures such as:
BUG: unable to handle kernel NULL pointer dereference at 0000000000000010
RIP: 0010:driver_xyz_process+0x5a/0x120 [driver_xyz]
Call Trace:
worker_thread+0x8f/0x1a0
kthread+0xef/0x120
ret_from_fork+0x2c/0x40
Tainted: G B W OE 5.14.0-xyz #1
Correlate symbols and inspect the faulting frame:
crash> sym driver_xyz_process
crash> dis -l driver_xyz_process+0x5a
crash> bt
crash> set -p <pid_of_worker>
crash> bt -f # show full frames with arguments
crash> struct task_struct <task_addr>
Representative outputs:
# vmcore-dmesg (panic excerpt)
[ 1234.567890] Kernel panic - not syncing: Fatal exception
[ 1234.567891] CPU: 7 PID: 4123 Comm: kworker/u16:2 Tainted: G B W OE 5.14.0-xyz #1
[ 1234.567893] Hardware name: Generic XYZ/ABC, BIOS 1.2.3 01/01/2025
[ 1234.567895] Workqueue: events_unbound driver_xyz_wq
[ 1234.567897] RIP: 0010:driver_xyz_process+0x5a/0x120 [driver_xyz]
[ 1234.567901] Call Trace:
[ 1234.567905] worker_thread+0x8f/0x1a0
[ 1234.567906] kthread+0xef/0x120
[ 1234.567907] ret_from_fork+0x2c/0x40
crash> sys
KERNEL: /usr/lib/debug/lib/modules/5.14.0-xyz/vmlinux
DUMPFILE: /var/crash/vmcore [PARTIAL DUMP]
CPUS: 32
DATE: Tue Oct 14 10:22:31 2025
UPTIME: 02:14:58
LOAD AVERAGE: 6.14, 6.02, 5.77
PANIC: "Kernel panic - not syncing: Fatal exception"
PID: 4123
COMMAND: "kworker/u16:2"
TASK: ffff8b2a7f1f0c00 [THREAD_INFO: ffffb2f1c2d2a000]
CPU: 7
STATE: TASK_RUNNING (PANIC)
crash> ps
PID PPID CPU TASK ST %MEM VSZ RSS COMM
> 4123 2 7 ffff8b2a7f1f0c00 RU 0.1 0 0 kworker/u16:2
1 0 0 ffff8b2a70000180 IN 0.0 16272 1308 systemd
532 1 2 ffff8b2a703f9b40 IN 0.2 912312 80324 containerd
987 532 5 ffff8b2a7a2fcd00 IN 0.4 1452312 231212 kubelet
crash> bt
PID: 4123 TASK: ffff8b2a7f1f0c00 CPU: 7 COMMAND: "kworker/u16:2"
#0 [ffffb2f1c2d2be78] machine_kexec at ffffffff914b3e10
#1 [ffffb2f1c2d2bec8] __crash_kexec at ffffffff915a1c32
#2 [ffffb2f1c2d2bf28] panic at ffffffff914c2a9d
#3 [ffffb2f1c2d2bf80] oops_end at ffffffff9148df90
#4 [ffffb2f1c2d2bfb0] page_fault_oops at ffffffff9148e4b5
#5 [ffffb2f1c2d2bfe0] exc_page_fault at ffffffff91abc7e1
#6 [ffffb2f1c2d2c018] asm_exc_page_fault at ffffffff91c0133e
#7 [ffffb2f1c2d2c048] driver_xyz_process+0x5a/0x120 [driver_xyz]
#8 [ffffb2f1c2d2c0a0] worker_thread+0x8f/0x1a0
#9 [ffffb2f1c2d2c0e0] kthread+0xef/0x120
#10 [ffffb2f1c2d2c110] ret_from_fork+0x2c/0x40
crash> kmem -i
PAGES TOTAL PERCENTAGE
TOTAL MEM 3276800 12.5 GB 100%
FREE 152345 595 MB 4%
USED 3124455 11.9 GB 96%
SHARED 80312 313 MB 2%
BUFFERS 49152 192 MB 1%
CACHED 842304 3.2 GB 26%
SLAB 921600 3.5 GB 28%
PAGECACHE 655360 2.5 GB 20%
ZONE DMA32: min 16224, low 20280, high 24336, scanned 1e6, order 3 allocs failing
Reclaimers: kswapd0: active, direct reclaim: observed
crash> log | head -n 6
<0>[ 1234.567890] Kernel panic - not syncing: Fatal exception
<4>[ 1234.567900] CPU: 7 PID: 4123 Comm: kworker/u16:2 Tainted: G B W OE
<4>[ 1234.567905] RIP: 0010:driver_xyz_process+0x5a/0x120 [driver_xyz]
<6>[ 1234.567950] Workqueue: events_unbound driver_xyz_wq
Actionable patterns:
- Null-dereference at a deref site → check expected invariants and lifetime rules for the object; validate RCU usage (
rcu_read_lock()/_unlock()pairs) and reference counting (kref,refcount_t). - Use-after-free → examine slab allocator metadata around the pointer;
kmemandrd -p(raw reads) can validate freelist poisoning. - Interrupt vs thread context → verify hardirq/softirq context in
bt; ensure lock acquisition order obeys documented lockdep dependencies.
If tainted by proprietary modules (OE), ensure matching module debuginfo is loaded so frames resolve cleanly. Validate module list:
crash> mod
From here, produce a minimal repro and map the faulting path to specific source lines using dis -l and DWARF line tables; attach exact register state and call trace to the fix.
Example 2 — Out-Of-Memory (OOM) and Panic-on-OOM
By default, OOM does not produce a vmcore because the kernel kills a task to free memory and continues. For deterministic forensics on pathological memory pressure, set vm.panic_on_oom=1 or 2 so the system panics and kdump captures a vmcore.
Pre-incident configuration:
sysctl -w vm.panic_on_oom=2
sysctl -w kernel.panic=15
After the event, extract the OOM report:
vmcore-dmesg /var/crash/vmcore | grep -A40 -B10 -n "Out of memory"
Example OOM excerpt:
[ 4321.000001] Out of memory: Killed process 29876 (jav a) total-vm:16384000kB, anon-rss:15500000kB, file-rss:12000kB, shmem-rss:0kB, UID:1000 pgtables:30240kB oom_score_adj:0
[ 4321.000015] oom_reaper: reaped process 29876 (java), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB
[ 4321.000120] Memory cgroup out of memory: Killed process 30555 (python) in cgroup /kubepods/besteffort/pod123/xyz
[ 4321.000200] Node 0 DMA32: free:152kB min:16224kB low:20280kB high:24336kB active_anon:10123456kB inactive_anon:1123456kB active_file:123456kB inactive_file:654321kB unevictable:0kB
[ 4321.000250] kswapd0: node 0, oom: task failed order:3, mode:0x24201ca(GFP_HIGHUSER_MOVABLE|__GFP_ZERO)
Selected crash views for OOM analysis:
crash> kmem -i
PAGES TOTAL PERCENTAGE
TOTAL MEM 3276800 12.5 GB 100%
FREE 20480 80 MB 0%
USED 3256320 12.4 GB 99%
CACHED 131072 512 MB 4%
SLAB 983040 3.7 GB 30%
Direct reclaim active; high-order allocations failing (order:3)
crash> ps -m | head -n 5
PID VSZ RSS COMM
29876 16384000 15500000 java
30555 2048000 1800000 python
987 1452312 231212 kubelet
Interpretation checklist inside crash:
crash> kmem -i # zones, watermarks, reclaimers state
crash> kmem -s # slab usage; look for runaway caches
crash> ps -m # memory stats per task
crash> vtop <task> <va> # translate VA to PFN to inspect mapping
crash> files -p <PID> # fd pressure and mmaps
crash> p sysctl_oom_dump_tasks
crash> log # OOM killer selection rationale, constraints
Indicators:
oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=...shows the policy path;score/oom_score_adjdetermine the victim.- Stalled reclaim (
kswapd,direct reclaim) with highorderallocations failing → likely hugepages, GFP_ATOMIC depletion, or CMA stress. - One slab consuming disproportionate memory → e.g., runaway
dentryorkmalloc-64due to leak; confirm withkmem -Sand inspect suspects via object walkers if available.
If OOM was triggered by a specific container/cgroup, use cgroup-aware views (kernel dependent):
crash> p memory.stat @<memcg_addr>
Correlating vmcore with Source and Binaries
Always analyze with the exact build artifacts of the panicked kernel:
vmlinuxand module.debugfiles must match theuname -rand build ID of the running kernel at the time of panic.- Mismatches lead to wrong type layouts, invalid offsets, and misleading backtraces.
- On distros with split debuginfo, install the
debuginfopackages for the precise NVR (Name-Version-Release) string.
Crash Analysis Cheat Sheet
vmcore-dmesg: panic reason, oops, OOM logs; fastest high-signal overview.sys: kernel build, CPU count, uptime, panic string, current task/CPU.ps/ps -m: runnable tasks;-madds memory stats per task.bt/bt -f: backtrace of current or selected task with frames/args.kmem -i/-s/-S: memory inventory; slabs by cache; cache detail.log: kernel ring buffer reconstructed from vmcore.mod: loaded modules and taint state.files -p <PID>: file descriptors and mmaps for a task.irq: hardirq/softirq state.vtop <task> <va>: VA→PFN translation; inspect mappings around suspect pages.
References and Further Reading
- Crash utility: https://crash-utility.github.io/
- makedumpfile project: https://github.com/makedumpfile/makedumpfile
- Upstream kdump guide: https://www.kernel.org/doc/html/latest/admin-guide/kdump/kdump.html
- Ubuntu Kernel Crash Dump Recipe: https://wiki.ubuntu.com/Kernel/CrashdumpRecipe
- Fedora kdump guide: https://docs.fedoraproject.org/en-US/fedora-coreos/debugging-kernel-crashes/
3 - Enabling Automatic Kernel Crash Collection with kdump
How to automatically enable and configure kdump crash collection on Linux systems using the kdump-enabler script.
Automatic Enablement of Kernel Crash Dump Collection with kdump-enabler
This article explains how to automatically enable and configure kernel crash dump (kdump) collection on Linux systems using the kdump-enabler script. This approach works across multiple distributions and simplifies the process of preparing your system to collect crash dumps for troubleshooting and analysis.
Overview
kdump-enabler is a Bash script that automates the setup of kdump:
- Installs required packages
- Configures the crashkernel parameter in GRUB
- Enables and starts the kdump service
- Sets up SysRq for manual crash triggering
- Creates backups of configuration files before changes
- Supports Ubuntu, Debian, RHEL, CentOS, Fedora, openSUSE, Arch Linux, and more
Prerequisites
- Root privileges (run with
sudo) - systemd-based Linux distribution
- GRUB bootloader
- Sufficient disk space in
/var/crashfor crash dumps
Installation
Clone the repository and run the script:
git clone https://github.com/samatild/kdump-enabler.git
cd kdump-enabler
sudo ./kdump-enabler.sh
Or download and run directly:
curl -O https://raw.githubusercontent.com/samatild/kdump-enabler/main/kdump-enabler.sh
chmod +x kdump-enabler.sh
sudo ./kdump-enabler.sh
Usage
Run the script interactively:
sudo ./kdump-enabler.sh
Or use options for automation:
sudo ./kdump-enabler.sh -y # Non-interactive mode
sudo ./kdump-enabler.sh --check-only # Only check current configuration
sudo ./kdump-enabler.sh --no-sysrq # Skip SysRq crash enablement
What the Script Does
- Detects your Linux distribution and package manager
- Checks current kdump status
- Installs required packages
- Configures crashkernel parameter in GRUB based on system RAM
- Enables kdump service at boot and starts it
- Enables SysRq for manual crash triggering
- Creates crash dump directory at
/var/crash
Post-Installation
After running the script, reboot your system for the crashkernel parameter to take effect:
sudo reboot
Verify kdump is working:
- Ubuntu/Debian:
sudo kdump-tools test sudo systemctl status kdump-tools - RHEL/CentOS/Fedora:
sudo kdumpctl showmem sudo systemctl status kdump - Check crashkernel:
cat /proc/cmdline | grep crashkernel - Check SysRq:
cat /proc/sys/kernel/sysrq # Should output: 1
Examples
Below are examples of running the script on different distributions and with various options, along with the kinds of output you can expect.
Interactive run (Ubuntu/Debian)
sudo ./kdump-enabler.sh
# Output (abridged):
╔══════════════════════════════════════════════════════════════╗
║ KDUMP ENABLER v1.0.0 ║
╚══════════════════════════════════════════════════════════════╝
[INFO] Detecting Linux distribution...
[SUCCESS] Detected: Ubuntu 22.04
[INFO] Package manager: apt
[INFO] Checking current kdump configuration...
[WARNING] No crashkernel parameter found in kernel command line
[WARNING] kdump service exists but is not active
[WARNING] System requires kdump configuration
[WARNING] This script will:
1. Install kdump packages (linux-crashdump kdump-tools kexec-tools)
2. Configure crashkernel parameter in GRUB
3. Enable and start kdump service
4. Enable SysRq crash trigger
5. Require a system reboot to complete setup
Do you want to continue? [y/N] y
[INFO] Installing required packages...
... apt-get update -qq
... apt-get install -y linux-crashdump kdump-tools kexec-tools
[SUCCESS] Packages installed successfully
[INFO] Configuring crashkernel parameter...
[INFO] Recommended crashkernel size: 384M (Total RAM: 12GB)
... updating /etc/default/grub
... running update-grub
[SUCCESS] GRUB configuration updated
[INFO] Configuring kdump settings...
... setting USE_KDUMP=1 in /etc/default/kdump-tools
[SUCCESS] kdump-tools configured
[INFO] Enabling kdump service...
[SUCCESS] kdump service enabled at boot
[WARNING] kdump service will start after reboot (crashkernel parameter needs to be loaded)
[INFO] Enabling SysRq crash trigger...
[SUCCESS] SysRq enabled for current session
[SUCCESS] SysRq configuration persisted to /etc/sysctl.conf
╔════════════════════════════════════════════════════════════════╗
║ KDUMP SETUP COMPLETED ║
╚════════════════════════════════════════════════════════════════╝
IMPORTANT: A system reboot is required to apply all changes!
Non-interactive run (auto-confirm)
sudo ./kdump-enabler.sh -y
# Output differences:
# - Skips confirmation prompts
# - Performs install/configuration immediately
Check-only mode (no changes)
sudo ./kdump-enabler.sh --check-only
# Output (abridged):
[INFO] Checking current kdump configuration...
[WARNING] No crashkernel parameter found in kernel command line
[WARNING] kdump service not found
[INFO] Crash dump directory: /var/crash (0 dumps found)
# Exits after status check without installing or modifying anything
Skip SysRq enablement
sudo ./kdump-enabler.sh -y --no-sysrq
# Output differences:
# - Does not enable SysRq or persist sysctl settings
# - All other steps (packages, GRUB, service) proceed
RHEL/Fedora example highlights
sudo ./kdump-enabler.sh -y
# Output (abridged):
[SUCCESS] Detected: Red Hat Enterprise Linux 9
[INFO] Package manager: yum
[INFO] Installing required packages...
... yum install -y kexec-tools
[SUCCESS] Packages installed successfully
[INFO] Configuring crashkernel parameter...
... updating /etc/default/grub
... grub2-mkconfig -o /boot/grub2/grub.cfg
[SUCCESS] GRUB2 configuration updated
[INFO] Configuring kdump settings...
... ensuring path /var/crash in /etc/kdump.conf
... setting core_collector makedumpfile -l --message-level 1 -d 31
[SUCCESS] kdump.conf configured
Testing Crash Dumps
⚠️ Warning: The following will immediately crash your system and generate a dump.
echo c | sudo tee /proc/sysrq-trigger
After reboot, check for crash dumps:
ls -lh /var/crash/
Troubleshooting
- Ensure crashkernel is loaded:
cat /proc/cmdline | grep crashkernel - Reboot after running the script
- Check available memory and disk space
- View service logs:
sudo journalctl -u kdump -xe - Update GRUB if needed and reboot
References
For more details, see the kdump-enabler GitHub repository.
4 - Kernel Mode vs User Mode: Privilege Levels and System Call Execution
Deep technical explanation of CPU privilege levels, kernel mode vs user mode execution contexts, system call mechanisms, memory protection, and security implications in the Linux kernel.
CPU Privilege Levels and Execution Contexts
Summary
Modern processors implement hardware-enforced privilege levels to isolate untrusted user code from critical kernel services. Linux uses two primary modes: kernel mode (ring 0, CPL 0, EL1) and user mode (ring 3, CPL 3, EL0). Kernel mode grants unrestricted access to CPU features, physical memory, I/O ports, and privileged instructions. User mode restricts access to a virtualized, isolated address space and requires kernel mediation for hardware resources. The transition between modes occurs via system calls, interrupts, and exceptions, all managed by the kernel’s interrupt and system call handlers. Understanding this separation is fundamental to security, performance optimization, and kernel debugging.
CPU Privilege Levels (Architecture Overview)
x86/x86-64 Privilege Rings
The x86 architecture defines four privilege levels (rings 0-3), though Linux uses only rings 0 and 3:

- Ring 0 (Kernel Mode): Highest privilege, executes kernel code, device drivers, interrupt handlers
- Ring 1-2: Unused by Linux (historically used for device drivers or hypervisors)
- Ring 3 (User Mode): Lowest privilege, executes user applications
Current Privilege Level (CPL): Stored in the lower 2 bits of the CS (Code Segment) register:
CPL=0: Kernel modeCPL=3: User mode
Kernel source: arch/x86/include/asm/segment.h
// Simplified CPL check macros
#define user_mode(regs) (((regs)->cs & SEGMENT_RPL_MASK) == USER_CS)
#define kernel_mode(regs) (!user_mode(regs))
ARM64 Exception Levels
ARM64 uses Exception Levels (EL0-EL3):

- EL0 (User Mode): Applications and user-space code
- EL1 (Kernel Mode): Linux kernel, hypervisor in some configurations
- EL2 (Hypervisor): Virtualization layer (KVM, Xen)
- EL3 (Secure Monitor): TrustZone secure world
Current Exception Level (EL): Stored in CurrentEL system register (bits [3:2])
Kernel source: arch/arm64/include/asm/ptrace.h
#define PSR_MODE_EL0t 0x00000000
#define PSR_MODE_EL1t 0x00000004
#define PSR_MODE_EL1h 0x00000005
Kernel Mode Characteristics
Privileges and Capabilities
1. Unrestricted Memory Access
- Direct access to physical memory addresses
- Can read/write kernel data structures
- Access to kernel address space (typically
0xffff800000000000and above on x86-64) - Can modify page tables, MMU configuration
2. Privileged Instructions
cli/sti(disable/enable interrupts)lgdt/lidt(load GDT/IDT)mov crX(control register access)in/out(I/O port access)hlt(halt CPU)wrmsr/rdmsr(Model-Specific Registers)
3. Interrupt and Exception Handling
- Can install interrupt handlers
- Access to interrupt controller (APIC, GIC)
- Exception vector table modification
4. System Control
- CPU scheduling decisions
- Process creation/destruction
- File system operations
- Network stack management
Kernel example - Direct memory access:
// Kernel can directly access physical memory
void *phys_addr = __va(0x1000000); // Convert physical to virtual
unsigned long value = *(unsigned long *)phys_addr;
// User mode cannot do this - would cause segmentation fault
Kernel Mode Execution Contexts
1. Process Context
- Executing on behalf of a user process (system call handler)
- Has associated
task_struct, user-space memory mappings - Can sleep, be preempted
- Example:
read(),write(),open()syscall handlers
2. Interrupt Context
- Executing in response to hardware interrupt
- No associated process (
currentmay point to interrupted process) - Cannot sleep, very limited blocking operations
- Must be fast and non-blocking
- Example: Network packet received, timer interrupt
3. Softirq/Tasklet Context
- Deferred interrupt processing
- Can run in interrupt context or
ksoftirqdthread - Similar constraints to interrupt context
- Example: Network packet processing, timer callbacks
Kernel source - Process context check:
// arch/x86/kernel/entry_64.S
ENTRY(entry_SYSCALL_64)
// Save user context
SWAPGS
movq %rsp, PER_CPU_VAR(cpu_current_top_of_stack)
// Switch to kernel stack
movq PER_CPU_VAR(cpu_current_top_of_stack), %rsp
// Now in kernel mode, process context
call do_syscall_64
User Mode Characteristics
Restrictions and Isolation
1. Virtual Memory Only
- Cannot access physical addresses directly
- Limited to virtual address space (typically
0x0000000000000000to0x00007fffffffffffon x86-64) - Page tables managed by kernel, not user-space
- Segmentation fault on invalid access
2. No Privileged Instructions
- Attempting privileged instructions causes General Protection Fault (#GP)
- Trapped by kernel, typically results in
SIGSEGVto process
3. System Call Interface
- Must use system calls to request kernel services
- System calls are the controlled entry point to kernel mode
- Each syscall has defined parameters and return values
4. Process Isolation
- Each process has independent virtual address space
- Cannot directly access other processes’ memory
- Inter-process communication requires kernel mediation (shared memory, pipes, sockets)
User-space example - Attempting privileged operation:
// This will fail in user mode
int main() {
unsigned long cr0;
asm volatile("mov %%cr0, %0" : "=r"(cr0)); // Privileged instruction
// Result: SIGSEGV - Segmentation fault
return 0;
}
User-space example - Valid system call:
// User mode must use system calls
int main() {
int fd = open("/etc/passwd", O_RDONLY); // System call
if (fd < 0) {
perror("open");
return 1;
}
close(fd); // System call
return 0;
}
Mode Transitions: System Calls
System Call Mechanism
System calls are the controlled mechanism for transitioning from user mode to kernel mode. The transition involves:
- User-space preparation: Set up syscall number and arguments
- Hardware trap: CPU switches to kernel mode via special instruction
- Kernel handler: Kernel validates and executes requested operation
- Return: Kernel switches back to user mode with result
x86-64 System Call Interface

Syscall instruction (syscall):
- Fastest method on x86-64
- System call number in
%rax - Arguments in
%rdi,%rsi,%rdx,%r10,%r8,%r9 - Return value in
%rax - Return address in
%rcx
Kernel source: arch/x86/entry/entry_64.S
// User-space syscall invocation (glibc wrapper)
static inline long __syscall0(long n) {
long ret;
asm volatile ("syscall" : "=a"(ret) : "a"(n) : "rcx", "r11", "memory");
return ret;
}
// Kernel entry point
ENTRY(entry_SYSCALL_64)
UNWIND_HINT_EMPTY
// Swap GS to kernel space
swapgs
// Save user-space registers
movq %rsp, PER_CPU_VAR(cpu_current_top_of_stack)
// Load kernel stack
movq PER_CPU_VAR(cpu_current_top_of_stack), %rsp
// Call C handler
call do_syscall_64
Alternative: int 0x80 (legacy):
- Slower, uses interrupt mechanism
- Still supported for 32-bit compatibility
- Uses interrupt descriptor table (IDT)
ARM64 System Call Interface
svc (Supervisor Call) instruction:
- System call number in
x8(W8) - Arguments in
x0-x7 - Return value in
x0
Kernel source: arch/arm64/kernel/entry.S
// User-space syscall invocation
long syscall(long n, ...) {
register long ret asm("x0");
register long syscall_nr asm("x8") = n;
asm volatile ("svc #0" : "=r"(ret) : "r"(syscall_nr) : "memory");
return ret;
}
System Call Handler Flow
Kernel source: kernel/sys.c, arch/x86/entry/common.c
// Simplified syscall handler
__visible noinstr void do_syscall_64(struct pt_regs *regs, int nr) {
// Validate syscall number
if (likely(nr < NR_syscalls)) {
// Get syscall function pointer
syscall_fn_t syscall_fn = syscall_table[nr];
// Execute syscall (still in kernel mode)
regs->ax = syscall_fn(regs);
} else {
regs->ax = -ENOSYS;
}
// Return to user mode
syscall_exit_to_user_mode(regs);
}
Practical example - Tracing system calls:
# Trace all syscalls made by a process
strace -e trace=all ls -l
# Example output:
# openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
# read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0\360\3\2\0\0\0\0\0"..., 832) = 832
# close(3) = 0
# openat(AT_FDCWD, ".", O_RDONLY|O_NONBLOCK|O_CLOEXEC|O_DIRECTORY) = 3
# getdents64(3, /* 5 entries */, 32768) = 144
# close(3) = 0
Memory Protection and Address Spaces
Virtual Address Space Layout
x86-64 User-Space (Linux):
0x0000000000000000 - 0x00007fffffffffff: User-space (128 TB)
├─ 0x0000000000400000: Code segment (.text)
├─ 0x00007fffff000000: Stack (grows downward)
├─ 0x00007ffffffde000: vDSO (virtual dynamic shared object)
└─ 0x00007ffffffff000: Stack guard page
x86-64 Kernel-Space:
0xffff800000000000 - 0xffffffffffffffff: Kernel-space (128 TB)
├─ 0xffff888000000000: Direct mapping of physical memory
├─ 0xffffc90000000000: vmalloc area
├─ 0xffffea0000000000: Vmemmap (struct page array)
└─ 0xffffffff80000000: Kernel code (text segment)
Kernel source: arch/x86/include/asm/page_64_types.h
#define __PAGE_OFFSET_BASE _AC(0xffff880000000000, UL)
#define __PAGE_OFFSET __PAGE_OFFSET_BASE
#define __START_KERNEL_map _AC(0xffffffff80000000, UL)
Page Table Protection
Page Table Entry (PTE) flags:
- User/Supervisor (U/S) bit: Controls user vs kernel access
U/S=0: Kernel-only pages (kernel mode access)U/S=1: User-accessible pages (both modes)
- Read/Write (R/W) bit: Controls write permissions
- Execute Disable (NX) bit: Prevents code execution (DEP/XN)
Kernel source: arch/x86/include/asm/pgtable_types.h
#define _PAGE_BIT_PRESENT 0
#define _PAGE_BIT_RW 1
#define _PAGE_BIT_USER 2
#define _PAGE_BIT_PWT 3
#define _PAGE_BIT_PCD 4
#define _PAGE_BIT_ACCESSED 5
#define _PAGE_BIT_DIRTY 6
#define _PAGE_BIT_PSE 7
#define _PAGE_BIT_PAT 7
#define _PAGE_BIT_GLOBAL 8
#define _PAGE_BIT_SOFTW1 9
#define _PAGE_BIT_SOFTW2 10
#define _PAGE_BIT_SOFTW3 11
#define _PAGE_BIT_PAT_LARGE 12
#define _PAGE_BIT_SPECIAL _PAGE_BIT_SOFTW1
#define _PAGE_BIT_CPA_TEST _PAGE_BIT_SOFTW1
#define _PAGE_BIT_NX 63
Practical example - Checking page permissions:
# View memory mappings of a process
cat /proc/self/maps
# Example output:
# 00400000-00401000 r-xp 00000000 08:01 123456 /bin/cat (executable, read-only)
# 00600000-00601000 r--p 00000000 08:01 123456 /bin/cat (read-only data)
# 00601000-00602000 rw-p 00001000 08:01 123456 /bin/cat (read-write data)
# 7fff00000000-7fff00001000 rw-p 00000000 00:00 0 (stack, read-write)
# ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 (vsyscall, kernel-managed)
Segmentation Fault Handling
When user-mode code attempts invalid access:
- CPU generates page fault (#PF exception)
- Kernel page fault handler (
do_page_fault()) executes - Kernel checks:
- Address validity
- Permissions (U/S bit, R/W bit)
- If invalid → send
SIGSEGVto process - If valid (copy-on-write, lazy allocation) → fix mapping and resume
Kernel source: arch/x86/mm/fault.c
static void
__do_page_fault(struct pt_regs *regs, unsigned long error_code,
unsigned long address) {
struct vm_area_struct *vma;
struct mm_struct *mm = current->mm;
// Check if fault occurred in kernel mode
if (unlikely(fault_in_kernel_space(address))) {
// Kernel-mode fault handling
do_kern_addr_fault(regs, error_code, address);
return;
}
// User-mode fault
vma = find_vma(mm, address);
if (!vma) {
// Invalid address - send SIGSEGV
bad_area(regs, error_code, address);
return;
}
// Check permissions
if (unlikely(access_error(error_code, vma))) {
bad_area_access_error(regs, error_code, address, vma);
return;
}
// Valid fault - handle (COW, lazy allocation, etc.)
fault = handle_mm_fault(vma, address, flags, regs);
}
Interrupts and Exceptions
Interrupt Handling Flow
Hardware interrupt sequence:
- Hardware device asserts interrupt line
- CPU finishes current instruction
- CPU switches to kernel mode (CPL=0)
- CPU saves user context (registers, return address)
- Kernel interrupt handler executes
- Kernel returns to user mode (or schedules different task)
Kernel source: arch/x86/entry/entry_64.S
// Interrupt entry point
ENTRY(common_interrupt)
// Save all registers
SAVE_ALL
// Disable interrupts (if needed)
cli
// Call C interrupt handler
call do_IRQ
// Restore and return
RESTORE_ALL
iretq
Exception Types
Faults (correctable):
- Page fault (#PF): Virtual memory access violation
- General Protection Fault (#GP): Invalid memory access, privilege violation
- Division Error (#DE): Divide by zero
Traps (instruction completes):
- Breakpoint (#BP):
int3instruction, debugger breakpoints - Overflow (#OF): Arithmetic overflow
Aborts (severe errors):
- Double Fault (#DF): Exception during exception handling
- Machine Check (#MC): Hardware error
All exceptions transition to kernel mode for handling.
Security Implications
Why Separation Matters
1. Process Isolation
- User processes cannot access each other’s memory
- Kernel enforces access control via page tables
- Prevents malicious or buggy programs from affecting others
2. Resource Protection
- Hardware resources (I/O ports, MSRs) protected from user access
- File system integrity maintained by kernel
- Network stack isolation prevents packet manipulation
3. Privilege Escalation Prevention
- User code cannot directly execute privileged instructions
- System calls are the only controlled entry point
- Kernel validates all requests before execution
Security example - Attempted privilege escalation:
// User-space code attempting to access kernel memory
int main() {
// Attempt to read kernel address space
unsigned long *kernel_addr = (unsigned long *)0xffffffff80000000;
unsigned long value = *kernel_addr; // Page fault!
// Result: SIGSEGV - Segmentation fault
// Kernel prevents user access to kernel memory
return 0;
}
System Call Validation
Kernel validates all syscall parameters:
// Example: open() syscall validation
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode) {
// Validate filename pointer (user-space address)
if (get_user(path, filename))
return -EFAULT;
// Validate path length
if (strnlen_user(path, MAX_PATH) > MAX_PATH)
return -ENAMETOOLONG;
// Check permissions
if (!may_open(&nd.path, acc_mode, open_flag))
return -EACCES;
// Proceed with file opening
return do_filp_open(dfd, tmp, &op);
}
Practical Examples and Demonstrations
Example 1: Observing Mode Transitions
Trace system calls and mode switches:
# Install perf tools
sudo apt-get install linux-perf
# Trace syscalls with timing
sudo perf trace -e syscalls:sys_enter_openat,syscalls:sys_exit_openat ls
# Output shows:
# 0.000 openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
# 0.012 <... openat resumed> ) = 3
# Each line shows user->kernel->user transition
Example 2: Kernel vs User Memory Access
User-space program:
#include <stdio.h>
#include <unistd.h>
#include <sys/mman.h>
int main() {
// User-space memory allocation
void *user_addr = mmap(NULL, 4096, PROT_READ|PROT_WRITE,
MAP_PRIVATE|MAP_ANONYMOUS, -1, 0);
printf("User-space address: %p\n", user_addr);
*(int *)user_addr = 42; // OK - user can write to own memory
// Attempt kernel-space access
void *kernel_addr = (void *)0xffffffff80000000;
// *(int *)kernel_addr = 42; // Would cause SIGSEGV
return 0;
}
Kernel module (for comparison):
// Kernel module can access both
static int __init test_init(void) {
void *user_addr = (void *)0x400000; // User-space address
void *kernel_addr = (void *)0xffffffff80000000; // Kernel address
// Access kernel memory (requires proper mapping)
// unsigned long val = *(unsigned long *)kernel_addr;
// Access user memory (requires copy_from_user)
// unsigned long val;
// copy_from_user(&val, user_addr, sizeof(val));
return 0;
}
Example 3: System Call Overhead
Measure syscall overhead:
#include <stdio.h>
#include <sys/time.h>
#include <unistd.h>
int main() {
struct timeval start, end;
long iterations = 1000000;
gettimeofday(&start, NULL);
for (long i = 0; i < iterations; i++) {
getpid(); // System call
}
gettimeofday(&end, NULL);
long us = (end.tv_sec - start.tv_sec) * 1000000 +
(end.tv_usec - start.tv_usec);
printf("Average syscall time: %.2f nanoseconds\n",
(us * 1000.0) / iterations);
return 0;
}
// Typical output: ~200-500 nanoseconds per syscall
// This includes: user->kernel transition + handler + kernel->user return
Example 4: Inspecting Current Mode
Check if code is running in kernel or user mode:
# From user-space (always shows user mode)
cat /proc/self/status | grep State
# From kernel module (can check current mode)
# In kernel code:
if (user_mode(regs)) {
printk("Running in user mode\n");
} else {
printk("Running in kernel mode\n");
}
Kernel Internals: Mode Switching Code
Context Switch and Mode Return
Returning to user mode after syscall:
// arch/x86/entry/common.c
__visible noinstr void syscall_exit_to_user_mode(struct pt_regs *regs) {
// Check for pending work (signals, preemption)
exit_to_user_mode_prepare(regs);
// Restore user-space registers
__syscall_exit_to_user_mode_work(regs);
}
static __always_inline void __syscall_exit_to_user_mode_work(struct pt_regs *regs) {
// Restore GS (swap back to user GS)
swapgs;
// Return to user mode
// IRET instruction restores:
// - CS (code segment) -> CPL=3
// - SS (stack segment)
// - RFLAGS (flags register)
// - RIP (instruction pointer)
// - RSP (stack pointer)
}
Interrupt Return
Returning from interrupt handler:
// arch/x86/entry/entry_64.S
ENTRY(common_interrupt_return)
// Check if returning to user mode
testb $3, CS(%rsp)
jnz swapgs_restore_regs_and_return_to_usermode
// Returning to kernel mode
RESTORE_ALL
iretq
swapgs_restore_regs_and_return_to_usermode:
// Swap GS back to user mode
swapgs
RESTORE_ALL
iretq
Performance Considerations
System Call Overhead
Factors affecting syscall performance:
- Mode transition cost: ~50-100 CPU cycles
- Register save/restore: ~100-200 cycles
- Cache effects: TLB flushes, cache misses
- Handler execution: Varies by syscall (nanoseconds to microseconds)
Optimization techniques:
- vDSO (Virtual Dynamic Shared Object): Some syscalls (e.g.,
gettimeofday()) execute in user-space - Batch syscalls:
io_uring,sendmmsg()reduce per-call overhead - Avoid unnecessary syscalls: Cache results, use memory-mapped I/O
Reducing Mode Transitions
Example - Reducing gettimeofday() overhead:
// Traditional approach (syscall each time)
for (int i = 0; i < 1000; i++) {
gettimeofday(&tv, NULL); // 1000 syscalls
}
// Optimized approach (vDSO - no syscall)
#include <sys/time.h>
#include <time.h>
for (int i = 0; i < 1000; i++) {
clock_gettime(CLOCK_REALTIME, &ts); // May use vDSO, no syscall
}
Debugging and Inspection Tools
Identifying Mode Transitions
1. Using strace:
# Trace all syscalls (shows user->kernel transitions)
strace -c ls -l
# Output:
# % time seconds usecs/call calls errors syscall
# ------ ----------- ----------- --------- --------- ----------------
# 23.45 0.000234 234 1000 openat
# 15.23 0.000152 152 1000 read
# 10.12 0.000101 101 1000 close
2. Using perf:
# Sample syscall events
sudo perf record -e syscalls:sys_enter_* -a sleep 1
sudo perf report
# Trace syscall latency
sudo perf trace --duration 1
3. Using gdb with kernel:
# Attach to running kernel (requires kgdb)
(gdb) target remote /dev/ttyS0
(gdb) break do_syscall_64
(gdb) continue
# Breakpoint shows entry to kernel mode
Kernel Logging
Monitor mode transitions in kernel logs:
# Enable kernel debugging
echo 8 > /proc/sys/kernel/printk # Enable all log levels
# Watch for syscall-related messages
dmesg -w | grep -i "syscall\|fault\|segfault"
Common Pitfalls and Misconceptions
Misconception 1: “Kernel mode is always faster”
Reality: Mode transitions have overhead. Kernel mode itself isn’t faster; it’s necessary for privileged operations. User-space code can be faster for pure computation.
Misconception 2: “System calls are expensive”
Reality: Modern CPUs optimize syscall transitions. Overhead is typically 200-500 nanoseconds, negligible for most applications. I/O operations (disk, network) dominate latency, not syscall overhead.
Misconception 3: “Kernel code always runs in kernel mode”
Reality: Kernel code executes in kernel mode, but kernel threads can be scheduled like user processes. Interrupt handlers run in interrupt context, not process context.
Misconception 4: “User-space cannot access kernel memory”
Reality: User-space can access kernel memory through /proc, /sys, and mmap() of kernel-exported memory (e.g., /dev/mem with proper permissions). The kernel controls what is exposed.
References and Further Reading
- Intel 64 and IA-32 Architectures Software Developer’s Manual: Volume 3A (System Programming Guide) - Privilege levels and protection
- ARM Architecture Reference Manual: Exception levels and privilege model
- Linux Kernel Source:
arch/x86/entry/(system call and interrupt entry code) - Understanding the Linux Kernel (3rd ed.): Chapter 1 (Introduction), Chapter 3 (Processes)
- Linux Device Drivers (3rd ed.): Chapter 9 (Interrupt Handling)
- man 2 syscalls: System call documentation
- man 2 syscall: Generic system call wrapper
Note: The distinction between kernel mode and user mode is fundamental to operating system security and stability. All privileged operations must occur in kernel mode, while user applications run in isolated user mode with controlled access to system resources via system calls.
5 - Understanding CPU Statistics in Linux (/proc/stat)
Deep technical dive into CPU time accounting in Linux, covering user, nice, system, idle, iowait, irq, softirq, steal, guest, and guest_nice statistics with practical examples and kernel internals.
Kernel-Level CPU Time Accounting
Summary
The Linux kernel maintains precise, per-CPU time accounting across ten distinct execution contexts. These statistics, exposed via /proc/stat, represent cumulative jiffy counters (typically 1/100th or 1/1000th of a second) since system boot. Understanding these counters is essential for performance analysis, capacity planning, and diagnosing CPU contention, I/O bottlenecks, interrupt storms, and virtualization overhead.
The /proc/stat Interface
/proc/stat is a virtual file provided by the kernel’s proc filesystem. It contains system-wide statistics aggregated across all CPUs and individual per-CPU lines. The format is non-blocking and updated atomically by the kernel scheduler’s tick handler.
View the raw statistics:
cat /proc/stat
Example output:
cpu 225748 1981 87654 3456789 1234 456 789 1011 2222 3333
cpu0 56387 495 21916 864197 308 114 197 252 555 833
cpu1 56390 495 21917 864198 309 114 197 253 556 833
cpu2 56385 495 21910 864197 308 114 197 252 555 833
cpu3 56386 496 21911 864197 309 114 198 254 556 834
intr 1234567890 123456 123456 123456 ...
ctxt 87654321
btime 1705123456
processes 23456
procs_running 2
procs_blocked 0
softirq 123456 789 12345 1234 5678 9012 3456 7890 123 456 789
The first line (cpu) aggregates all CPUs; subsequent cpuN lines show per-CPU statistics. Each CPU line contains ten fields:
cpuX user nice system idle iowait irq softirq steal guest guest_nice
Note: All values are cumulative counters measured in jiffies (kernel ticks). To calculate percentages or rates, you must sample at two points in time and compute deltas.
Field-by-Field Breakdown
1. user (usr)
Kernel context: Time spent executing user-space code in normal priority processes.
Increment condition: Kernel tick handler (account_process_tick()) counts time when a process is running in user mode with default priority (nice value 0-0).
Kernel source: kernel/sched/cputime.c::account_user_time()
Example interpretation:
- High
usertime indicates CPU-bound applications - Typical range: 20-80% on interactive systems
- Can exceed 100% per CPU if multiple threads run concurrently (SMP accounting)
Practical example:
# Monitor user CPU time growth over 5 seconds
T1=$(grep '^cpu ' /proc/stat | awk '{print $2}')
sleep 5
T2=$(grep '^cpu ' /proc/stat | awk '{print $2}')
DELTA=$((T2 - T1))
HZ=$(getconf CLK_TCK) # Usually 100 or 1000
PERCENT=$(echo "scale=2; ($DELTA * 100) / ($HZ * 5)" | bc)
echo "User CPU usage: ${PERCENT}%"
Kernel implementation detail:
// Simplified representation of kernel accounting
void account_user_time(struct task_struct *p, u64 cputime)
{
p->utime += cputime;
if (task_nice(p) <= 0)
account_cputime_user(p, cputime);
}
2. nice
Kernel context: Time spent executing user-space code in niced processes (nice value < 0 means higher priority, > 0 means lower priority).
Increment condition: Same as user, but only when task_nice(p) != 0 (non-zero nice value).
Kernel source: kernel/sched/cputime.c::account_user_time() with nice check
Example interpretation:
- Non-zero values indicate processes with adjusted priorities
nice < 0: high-priority processes (e.g., RT priority mapped to nice)nice > 0: low-priority background tasks- Modern kernels may report 0 if no niced processes exist
Practical example:
# Find processes contributing to nice time
ps -eo pid,ni,comm,pcpu --sort=-pcpu | head -10
# Generate nice time by running a niced process
nice -n 19 dd if=/dev/zero of=/dev/null bs=1M count=1000 &
NICE_PID=$!
sleep 2
# Check nice time increment
grep '^cpu ' /proc/stat | awk '{print $3}'
Advanced: Nice value to priority mapping:
# Show nice values and their scheduling impact
for nice in -20 -10 0 10 19; do
echo "Nice $nice -> Priority: $((100 + nice))"
done
3. system (sys)
Kernel context: Time spent executing kernel code on behalf of user processes (system calls, kernel services).
Increment condition: Kernel tick handler counts time when the process is in kernel mode (handling syscalls, page faults, exceptions, etc.).
Kernel source: kernel/sched/cputime.c::account_system_time()
Example interpretation:
- High
systemtime indicates frequent syscalls or kernel processing - Typical range: 5-30% on normal systems
- Spikes suggest I/O-bound workloads, context switching, or kernel-intensive operations
50% may indicate kernel bottlenecks or driver issues
Practical example:
# Monitor system call rate (indirectly via system time)
T1=$(grep '^cpu ' /proc/stat | awk '{print $4}')
strace -c -e trace=all sleep 1 2>&1 | tail -1
T2=$(grep '^cpu ' /proc/stat | awk '{print $4}')
echo "System time delta: $((T2 - T1)) jiffies"
# High system time scenarios:
# 1. Frequent file I/O
dd if=/dev/urandom of=/tmp/test bs=4K count=10000
# 2. Network operations
curl -s https://example.com > /dev/null
# 3. Process creation
for i in {1..1000}; do true; done
Kernel code path:
// System time accounting during syscall
long sys_xyz(...) {
// Pre-syscall timestamp
account_system_time(current, cputime_before);
// ... kernel work ...
account_system_time(current, cputime_after);
}
4. idle
Kernel context: Time the CPU spent idle (no runnable tasks, waiting in idle loop).
Increment condition: Kernel idle loop (do_idle()) executes when the runqueue is empty. The idle task (PID 0, swapper) runs and increments this counter.
Kernel source: kernel/sched/idle.c::do_idle()
Example interpretation:
- High
idle= low CPU utilization - Idle time should decrease under load
100% - idle%≈ total CPU utilization- On SMP systems, one CPU can be idle while others are busy
Practical example:
# Calculate CPU utilization percentage
get_cpu_usage() {
local cpu_line=$(grep '^cpu ' /proc/stat)
local user=$(echo $cpu_line | awk '{print $2}')
local nice=$(echo $cpu_line | awk '{print $3}')
local system=$(echo $cpu_line | awk '{print $4}')
local idle=$(echo $cpu_line | awk '{print $5}')
local iowait=$(echo $cpu_line | awk '{print $6}')
local total=$((user + nice + system + idle + iowait))
local used=$((user + nice + system))
echo "scale=2; ($used * 100) / $total" | bc
}
# Monitor over time
while true; do
echo "$(date): CPU Usage: $(get_cpu_usage)%"
sleep 1
done
Idle loop internals:
// Simplified idle loop (arch-specific)
static void do_idle(void) {
while (1) {
if (need_resched()) {
schedule_idle();
continue;
}
// Enter low-power state (HLT, MWAIT, etc.)
arch_cpu_idle();
account_idle_time(cpu, cputime);
}
}
5. iowait
Kernel context: Time the CPU spent idle while waiting for I/O operations to complete.
Increment condition: CPU is idle (idle would increment) but there are outstanding I/O requests in flight. This is a special case of idle time.
Kernel source: kernel/sched/cputime.c::account_idle_time() with I/O pending check
Example interpretation:
- Indicates I/O-bound workloads
- High
iowaitsuggests disk/network bottlenecks - Important:
iowaitdoes NOT mean the CPU is busy; it’s idle time waiting for I/O - Combined with low
user/system= I/O bottleneck, not CPU bottleneck - Can be misleading on systems with async I/O (io_uring, etc.)
Practical example:
# Generate iowait by saturating disk I/O
dd if=/dev/zero of=/tmp/stress bs=1M count=10000 oflag=direct &
DD_PID=$!
# Monitor iowait growth
watch -n 1 "grep '^cpu ' /proc/stat | awk '{print \"iowait: \" \$6 \" jiffies\"}'"
# Stop the stress
kill $DD_PID
# Compare with actual I/O stats
iostat -x 1 5
Kernel accounting logic:
void account_idle_time(struct rq *rq, u64 cputime) {
if (nr_iowait_cpu(smp_processor_id()) > 0)
account_cputime_iowait(rq, cputime);
else
account_cputime_idle(rq, cputime);
}
Common misconception: iowait is NOT CPU time spent on I/O. The CPU is idle; the I/O device (disk controller, NIC) is busy.
6. irq (hardirq)
Kernel context: Time spent servicing hardware interrupts (IRQs).
Increment condition: Kernel interrupt handler executes. Each IRQ handler increments per-CPU and per-IRQ counters.
Kernel source: kernel/softirq.c, interrupt handlers
Example interpretation:
- High
irqindicates interrupt-heavy workloads (network, storage, timers) - Typical range: <1% on idle systems, 1-5% under load
- Spikes suggest hardware issues or misconfigured interrupt affinity
- Can be distributed via
smp_affinitymasks
Practical example:
# View interrupt distribution
cat /proc/interrupts
# Generate high IRQ load (network interrupts)
iperf3 -s &
SERVER_PID=$!
iperf3 -c localhost -t 30 -P 8 # 8 parallel streams
kill $SERVER_PID
# Monitor IRQ time
T1=$(grep '^cpu ' /proc/stat | awk '{print $7}')
sleep 5
T2=$(grep '^cpu ' /proc/stat | awk '{print $7}')
echo "IRQ time delta: $((T2 - T1)) jiffies"
# Set interrupt affinity (example: bind IRQ 24 to CPU 0)
echo 1 > /proc/irq/24/smp_affinity
Interrupt handler accounting:
irqreturn_t handle_irq_event(struct irq_desc *desc) {
u64 start = local_clock();
// ... handle interrupt ...
account_hardirq_time(current, local_clock() - start);
return IRQ_HANDLED;
}
7. softirq
Kernel context: Time spent executing softirqs (deferred interrupt processing, bottom halves).
Increment condition: Kernel softirq daemon (ksoftirqd) or direct softirq execution in interrupt context processes pending softirqs.
Kernel source: kernel/softirq.c::__do_softirq()
Softirq types (from include/linux/interrupt.h):
HI_SOFTIRQ: High-priority taskletsTIMER_SOFTIRQ: Timer callbacksNET_TX_SOFTIRQ: Network transmitNET_RX_SOFTIRQ: Network receiveBLOCK_SOFTIRQ: Block device I/O completionIRQ_POLL_SOFTIRQ: IRQ pollingTASKLET_SOFTIRQ: Normal taskletsSCHED_SOFTIRQ: Scheduler callbacksHRTIMER_SOFTIRQ: High-resolution timersRCU_SOFTIRQ: RCU callbacks
Example interpretation:
- High
softirqindicates deferred processing load (network, timers, RCU) - Network-heavy workloads show high
NET_RX_SOFTIRQ/NET_TX_SOFTIRQ - RCU-heavy systems (many CPUs) show high
RCU_SOFTIRQ - Softirq time can exceed 10% on network servers
Practical example:
# View softirq breakdown
cat /proc/softirq
# Example output:
# CPU0 CPU1 CPU2 CPU3
# HI: 0 0 0 0
# TIMER: 123456 123457 123458 123459
# NET_TX: 1234 1235 1236 1237
# NET_RX: 56789 56790 56791 56792
# BLOCK: 0 0 0 0
# IRQ_POLL: 0 0 0 0
# TASKLET: 12 13 14 15
# SCHED: 23456 23457 23458 23459
# HRTIMER: 0 0 0 0
# RCU: 345678 345679 345680 345681
# Generate NET_RX softirq load
iperf3 -s &
SERVER_PID=$!
iperf3 -c localhost -t 10 -P 16
kill $SERVER_PID
# Monitor softirq time growth
watch -n 1 "grep '^cpu ' /proc/stat | awk '{print \"softirq: \" \$8}'"
Softirq execution contexts:
// Softirqs can run in:
// 1. Interrupt return path (if pending)
irq_exit() {
if (in_interrupt() && local_softirq_pending())
invoke_softirq();
}
// 2. ksoftirqd kernel thread
static int ksoftirqd(void *data) {
while (!kthread_should_stop()) {
__do_softirq();
schedule();
}
}
// 3. Explicit raise (local_bh_enable, etc.)
8. steal
Kernel context: Time “stolen” by the hypervisor from a virtual CPU (only in virtualized environments).
Increment condition: Hypervisor preempts the guest VM’s virtual CPU to schedule other VMs or host tasks. The guest kernel detects this via paravirtualized time sources (e.g., KVM’s kvm_steal_time).
Kernel source: arch/x86/kernel/kvm.c::kvm_steal_time_setup()
Example interpretation:
- Only non-zero in VMs (KVM, Xen, VMware, Hyper-V)
- High
stealindicates host CPU overcommit or noisy neighbors 10% suggests VM should be migrated or host CPU capacity increased
stealtime is “lost” from the guest’s perspective
Practical example:
# Check if running in a VM
if [ -d /sys/devices/virtual/dmi/id ]; then
if grep -q "KVM\|VMware\|Xen\|Microsoft" /sys/devices/virtual/dmi/id/product_name 2>/dev/null; then
echo "Running in virtualized environment"
fi
fi
# Monitor steal time
watch -n 1 "grep '^cpu ' /proc/stat | awk '{print \"steal: \" \$9 \" jiffies\"}'"
# Calculate steal percentage
calc_steal_pct() {
local cpu_line=$(grep '^cpu ' /proc/stat)
local total=$(echo $cpu_line | awk '{sum=0; for(i=2;i<=NF;i++) sum+=$i; print sum}')
local steal=$(echo $cpu_line | awk '{print $9}')
echo "scale=2; ($steal * 100) / $total" | bc
}
KVM steal time mechanism:
// Host side (KVM)
static void record_steal_time(struct kvm_vcpu *vcpu) {
struct kvm_steal_time *st = vcpu->arch.st;
st->steal += current->sched_info.run_delay;
}
// Guest side (Linux kernel)
static void kvm_steal_time_setup(void) {
// Read steal time from shared page
steal = st->steal;
account_steal_time(steal);
}
9. guest
Kernel context: Time spent running a guest OS (nested virtualization or KVM guest time accounting).
Increment condition: Host kernel accounts time when a guest VM’s virtual CPU is executing. This is the inverse of steal from the host’s perspective.
Kernel source: kernel/sched/cputime.c::account_guest_time()
Example interpretation:
- Non-zero on hypervisor hosts running VMs
- Represents CPU time consumed by guest VMs
- In nested virtualization, a guest VM can itself host VMs
- Typically only relevant for hypervisor monitoring
Practical example:
# On a KVM host, monitor guest time
watch -n 1 "grep '^cpu ' /proc/stat | awk '{print \"guest: \" \$10}'"
# Compare with VM CPU usage (from host perspective)
virsh domstats --cpu <domain>
Guest time accounting:
// When guest VM executes on host CPU
void account_guest_time(struct task_struct *p, u64 cputime) {
account_cputime_guest(p, cputime);
// Guest time is also counted as user time from host perspective
account_user_time(p, cputime);
}
10. guest_nice
Kernel context: Time spent running niced guest OS processes (nested virtualization).
Increment condition: Same as guest, but for processes with non-zero nice values in the guest.
Kernel source: kernel/sched/cputime.c::account_guest_time() with nice check
Example interpretation:
- Parallel to
nicebut for guest VM processes - Rarely non-zero unless guests run niced workloads
- Mostly relevant for hypervisor capacity planning
Practical example:
# Monitor guest_nice (typically zero)
grep '^cpu ' /proc/stat | awk '{print "guest_nice: " $11}'
Complete CPU Utilization Calculation
To calculate accurate CPU percentages, sample /proc/stat at two points and compute deltas:
#!/bin/bash
# Comprehensive CPU statistics calculator
get_cpu_stats() {
grep '^cpu ' /proc/stat | awk '{
user=$2; nice=$3; system=$4; idle=$5;
iowait=$6; irq=$7; softirq=$8; steal=$9;
guest=$10; guest_nice=$11;
# Total is sum of all fields (idle included)
total = user + nice + system + idle + iowait + irq + softirq + steal
# Active time (excluding idle and iowait)
active = user + nice + system + irq + softirq
# Idle time (true idle + iowait)
idle_total = idle + iowait
print user, nice, system, idle, iowait, irq, softirq, steal, guest, guest_nice, total, active, idle_total
}'
}
# Sample 1
S1=($(get_cpu_stats))
sleep 1
# Sample 2
S2=($(get_cpu_stats))
# Calculate deltas
for i in {0..12}; do
DELTA[$i]=$((${S2[$i]} - ${S1[$i]}))
done
# Calculate percentages (assuming HZ=100)
HZ=100
TOTAL_DELTA=${DELTA[10]}
echo "CPU Statistics (1 second sample):"
echo "================================"
printf "User: %6.2f%%\n" $(echo "scale=2; (${DELTA[0]} * 100) / $TOTAL_DELTA" | bc)
printf "Nice: %6.2f%%\n" $(echo "scale=2; (${DELTA[1]} * 100) / $TOTAL_DELTA" | bc)
printf "System: %6.2f%%\n" $(echo "scale=2; (${DELTA[2]} * 100) / $TOTAL_DELTA" | bc)
printf "Idle: %6.2f%%\n" $(echo "scale=2; (${DELTA[3]} * 100) / $TOTAL_DELTA" | bc)
printf "IOWait: %6.2f%%\n" $(echo "scale=2; (${DELTA[4]} * 100) / $TOTAL_DELTA" | bc)
printf "IRQ: %6.2f%%\n" $(echo "scale=2; (${DELTA[5]} * 100) / $TOTAL_DELTA" | bc)
printf "SoftIRQ: %6.2f%%\n" $(echo "scale=2; (${DELTA[6]} * 100) / $TOTAL_DELTA" | bc)
printf "Steal: %6.2f%%\n" $(echo "scale=2; (${DELTA[7]} * 100) / $TOTAL_DELTA" | bc)
printf "Guest: %6.2f%%\n" $(echo "scale=2; (${DELTA[8]} * 100) / $TOTAL_DELTA" | bc)
printf "GuestNice: %6.2f%%\n" $(echo "scale=2; (${DELTA[9]} * 100) / $TOTAL_DELTA" | bc)
echo "================================"
printf "Total CPU Usage: %6.2f%%\n" $(echo "scale=2; (${DELTA[11]} * 100) / $TOTAL_DELTA" | bc)
Per-CPU Analysis
Individual CPU cores can have vastly different statistics:
# Show per-CPU breakdown
for cpu in $(grep '^cpu[0-9]' /proc/stat | cut -d' ' -f1); do
echo "=== $cpu ==="
grep "^$cpu " /proc/stat | awk '{
total = $2+$3+$4+$5+$6+$7+$8+$9
printf "User: %.1f%%, System: %.1f%%, Idle: %.1f%%, IOWait: %.1f%%\n",
($2*100)/total, ($4*100)/total, ($5*100)/total, ($6*100)/total
}'
done
Kernel Implementation Details
Tick Accounting
The kernel updates /proc/stat during periodic timer interrupts (tick handler):
// Simplified tick handler flow
void update_process_times(int user_tick) {
struct task_struct *p = current;
u64 cputime = cputime_one_jiffy;
if (user_tick) {
account_user_time(p, cputime);
} else {
account_system_time(p, cputime);
}
// Update per-CPU stats
account_cputime_index(cpu, index, cputime);
}
Counter Precision
- Jiffy resolution: Typically 1ms (HZ=1000) or 10ms (HZ=100)
- Cumulative counters: Never reset, wrap around after ~497 days (32-bit) or effectively never (64-bit)
- Atomic updates: Counters updated atomically to prevent race conditions
- Per-CPU storage: Reduces cache line contention
Reading /proc/stat Safely
The kernel provides a consistent snapshot:
// Kernel side: seq_file interface ensures atomic reads
static int stat_show(struct seq_file *p, void *v) {
// Lockless read of per-CPU counters
for_each_possible_cpu(cpu) {
sum_cpu_stats(cpu, &stats);
}
seq_printf(p, "cpu %llu %llu ...\n", stats.user, stats.nice, ...);
}
Advanced Use Cases
1. Real-time CPU Monitoring Script
#!/bin/bash
# Continuous CPU statistics monitor
HZ=$(getconf CLK_TCK)
INTERVAL=1
while true; do
clear
echo "CPU Statistics (refreshing every ${INTERVAL}s)"
echo "=============================================="
# Aggregate all CPUs
S1=$(grep '^cpu ' /proc/stat)
sleep $INTERVAL
S2=$(grep '^cpu ' /proc/stat)
# Parse and calculate
read -r u1 n1 s1 i1 w1 x1 y1 z1 st1 g1 gn1 <<< $(echo $S1 | awk '{print $2,$3,$4,$5,$6,$7,$8,$9,$10,$11}')
read -r u2 n2 s2 i2 w2 x2 y2 z2 st2 g2 gn2 <<< $(echo $S2 | awk '{print $2,$3,$4,$5,$6,$7,$8,$9,$10,$11}')
total=$(( (u2+n2+s2+i2+w2+x2+y2+z2) - (u1+n1+s1+i1+w1+x1+y1+z1) ))
if [ $total -gt 0 ]; then
printf "User: %5.1f%% [%8d jiffies]\n" $(echo "scale=1; (($u2-$u1)*100)/$total" | bc) $((u2-u1))
printf "Nice: %5.1f%% [%8d jiffies]\n" $(echo "scale=1; (($n2-$n1)*100)/$total" | bc) $((n2-n1))
printf "System: %5.1f%% [%8d jiffies]\n" $(echo "scale=1; (($s2-$s1)*100)/$total" | bc) $((s2-s1))
printf "Idle: %5.1f%% [%8d jiffies]\n" $(echo "scale=1; (($i2-$i1)*100)/$total" | bc) $((i2-i1))
printf "IOWait: %5.1f%% [%8d jiffies]\n" $(echo "scale=1; (($w2-$w1)*100)/$total" | bc) $((w2-w1))
printf "IRQ: %5.1f%% [%8d jiffies]\n" $(echo "scale=1; (($x2-$x1)*100)/$total" | bc) $((x2-x1))
printf "SoftIRQ: %5.1f%% [%8d jiffies]\n" $(echo "scale=1; (($y2-$y1)*100)/$total" | bc) $((y2-y1))
printf "Steal: %5.1f%% [%8d jiffies]\n" $(echo "scale=1; (($z2-$z1)*100)/$total" | bc) $((z2-z1))
printf "Guest: %5.1f%% [%8d jiffies]\n" $(echo "scale=1; (($g2-$g1)*100)/$total" | bc) $((g2-g1))
fi
echo "=============================================="
echo "Press Ctrl+C to exit"
sleep $((INTERVAL - 1))
done
2. Historical CPU Statistics Collection
#!/bin/bash
# Collect CPU stats over time for analysis
LOG_FILE="/tmp/cpu_stats.log"
INTERVAL=5
DURATION=3600 # 1 hour
echo "timestamp,user,nice,system,idle,iowait,irq,softirq,steal,guest,guest_nice" > $LOG_FILE
START=$(date +%s)
while [ $(($(date +%s) - START)) -lt $DURATION ]; do
TIMESTAMP=$(date +%s)
STATS=$(grep '^cpu ' /proc/stat | awk '{print $2","$3","$4","$5","$6","$7","$8","$9","$10","$11}')
echo "$TIMESTAMP,$STATS" >> $LOG_FILE
sleep $INTERVAL
done
# Analyze collected data
echo "Analysis complete. Log: $LOG_FILE"
3. Detect CPU Anomalies
#!/bin/bash
# Alert on unusual CPU statistics
THRESHOLD_IOWAIT=20 # Alert if iowait > 20%
THRESHOLD_STEAL=10 # Alert if steal > 10%
THRESHOLD_SOFTIRQ=15 # Alert if softirq > 15%
check_cpu_stats() {
S1=$(grep '^cpu ' /proc/stat)
sleep 1
S2=$(grep '^cpu ' /proc/stat)
read -r u1 n1 s1 i1 w1 x1 y1 z1 st1 g1 gn1 <<< $(echo $S1 | awk '{print $2,$3,$4,$5,$6,$7,$8,$9,$10,$11}')
read -r u2 n2 s2 i2 w2 x2 y2 z2 st2 g2 gn2 <<< $(echo $S2 | awk '{print $2,$3,$4,$5,$6,$7,$8,$9,$10,$11}')
total=$(( (u2+n2+s2+i2+w2+x2+y2+z2) - (u1+n1+s1+i1+w1+x1+y1+z1) ))
if [ $total -gt 0 ]; then
iowait_pct=$(echo "scale=1; (($w2-$w1)*100)/$total" | bc)
steal_pct=$(echo "scale=1; (($z2-$z1)*100)/$total" | bc)
softirq_pct=$(echo "scale=1; (($y2-$y1)*100)/$total" | bc)
if (( $(echo "$iowait_pct > $THRESHOLD_IOWAIT" | bc -l) )); then
echo "WARNING: High IOWait detected: ${iowait_pct}%"
fi
if (( $(echo "$steal_pct > $THRESHOLD_STEAL" | bc -l) )); then
echo "WARNING: High steal time detected: ${steal_pct}% (possible host overcommit)"
fi
if (( $(echo "$softirq_pct > $THRESHOLD_SOFTIRQ" | bc -l) )); then
echo "WARNING: High softirq time detected: ${softirq_pct}% (possible interrupt storm)"
fi
fi
}
check_cpu_stats
Relationship to Other Kernel Interfaces
/proc/loadavg
Load average is related but distinct:
- Load average = runnable tasks + uninterruptible sleep (I/O wait)
- CPU statistics = actual CPU time spent in each state
- High load + low CPU usage = I/O bottleneck
/proc/uptime
System uptime used to calculate rates:
uptime_seconds=$(awk '{print $1}' /proc/uptime)
cpu_jiffies=$(grep '^cpu ' /proc/stat | awk '{sum=0; for(i=2;i<=NF;i++) sum+=$i; print sum}')
HZ=$(getconf CLK_TCK)
cpu_time=$((cpu_jiffies / HZ))
echo "CPU time accumulated: ${cpu_time}s over ${uptime_seconds}s uptime"
top/htop Internals
Tools like top read /proc/stat and /proc/[pid]/stat to compute CPU percentages:
// Simplified top calculation
cpu_percent = (delta_user + delta_system) / delta_total * 100
Troubleshooting Scenarios
Scenario 1: High System Time
Symptoms: system time > 30%, slow application response
Investigation:
# Check syscall rate
strace -c -p $(pgrep -f <application>) 2>&1 | head -20
# Check context switch rate
vmstat 1 5
# Check kernel function profiling (requires perf)
perf top -g -p $(pgrep -f <application>)
Common causes:
- Frequent page faults
- Excessive system calls
- Kernel lock contention
- Driver issues
Scenario 2: High IOWait
Symptoms: iowait > 20%, system feels sluggish
Investigation:
# Check I/O wait queue depth
iostat -x 1 5
# Check block device statistics
cat /proc/diskstats
# Identify I/O-intensive processes
iotop -o
# Check filesystem I/O
df -h
mount | grep -E '(noatime|nodiratime)'
Common causes:
- Slow storage (HDD vs SSD)
- Saturated I/O bandwidth
- Swapping (check
/proc/meminfo) - Network filesystem latency
Scenario 3: High SoftIRQ Time
Symptoms: softirq > 15%, network performance issues
Investigation:
# Break down softirq types
watch -n 1 'cat /proc/softirq'
# Check network receive drops
cat /proc/net/softnet_stat
# Monitor network interrupts
cat /proc/interrupts | grep -i eth
# Check for receive livelock
ethtool -S <interface> | grep -i drop
Common causes:
- High network packet rate
- Small receive buffers
- Interrupt coalescing misconfiguration
- Network driver issues
Scenario 4: High Steal Time in VM
Symptoms: steal > 10%, VM performance degradation
Investigation:
# Confirm virtualization
systemd-detect-virt
# Check CPU pinning
virsh vcpuinfo <domain>
# Monitor from host perspective
virsh domstats <domain> --cpu
# Check for CPU overcommit
# (On host) virsh nodeinfo
Solutions:
- Migrate VM to less loaded host
- Increase host CPU capacity
- Use CPU pinning/affinity
- Enable CPU features (virtio, paravirtualization)
References and Further Reading
- Kernel Documentation:
Documentation/filesystems/proc.rst(CPU statistics section) - Kernel Source:
kernel/sched/cputime.c(CPU time accounting implementation) - man proc(5):
/proc/statformat documentation - Linux Performance and Tuning Guide: CPU accounting and analysis
- Understanding the Linux Kernel (3rd ed.): Chapter 4 (Interrupts and Exceptions), Chapter 7 (Kernel Synchronization)
Note: All statistics are cumulative since boot. To calculate rates or percentages, always sample at two points in time and compute deltas. The kernel tick rate (HZ) determines counter resolution and can be queried via getconf CLK_TCK.